平安校園")
絡(luò)教育-教育培訓(xùn)--江蘇教育黃頁")
套餐優(yōu)惠多多")

員考試 PHP教程 自考 注冊會計師 會計證 統(tǒng)統(tǒng)免費下")
假設(shè)我們有一張數(shù)據(jù)表 employee(員工表),該表有三個字段(列),分別是name、age 和address。假設(shè)表employee有上萬行數(shù)據(jù)(這公司還真大),現(xiàn)在需要從這個表中查找出所有名字是‘ZhangSan’的雇員信息,...

什么是索引?
假設(shè)我們有一張數(shù)據(jù)表 employee(員工表),該表有三個字段(列),分別是name、age 和address。假設(shè)表employee有上萬行數(shù)據(jù)(這公司還真大),現(xiàn)在需要從這個表中查找出所有名字是‘ZhangSan’的雇員信息,你會快速的寫出SQL語句:
select name,age,address from employee where name='ZhangSan'
如果數(shù)據(jù)庫還沒有索引這個東西,一旦我們運行這個SQL查詢,查找名字為ZhangSan的雇員的過程中,究竟會發(fā)生什么?數(shù)據(jù)庫不得不在employee表中的每一行查找并確定雇員的名字(name)是否為‘ZhangSan’。
由于我們想要得到每一個名字為ZhangSan的雇員信息,在查詢到第一個符合條件的行后,不能停止查詢,因為可能還有其他符合條件的行,所以必須一行一行的查找直到最后一行——這就意味數(shù)據(jù)庫不得不檢查上萬行數(shù)據(jù)才能找到所有名字為ZhangSan的雇員。這就是所謂的全表掃描(參見前文“執(zhí)行計劃”中type=ALL),顯然這種模式效率太慢,技術(shù)可能覺得無所謂,業(yè)務(wù)會拿刀砍你。
你會想為如此簡單的事情做全表掃描效率欠佳——數(shù)據(jù)庫是不是應(yīng)該更聰明一點呢?這就像用人眼從頭到尾瀏覽整張表,很慢也不優(yōu)雅,“索引”派上用場的時候到了,使用索引的全部意義就是:通過縮小一張表中需要查詢的記錄/行的數(shù)目來加快搜索的速度。
在關(guān)系型數(shù)據(jù)庫中,索引是一種單獨的、物理的對數(shù)據(jù)庫表中一列或多列的值進(jìn)行排序的一種存儲結(jié)構(gòu),它是某個表中一列或若干列值的集合和相應(yīng)的指向表中物理標(biāo)識這些值的數(shù)據(jù)頁的邏輯指針清單(定義真特么拗口)。大白話意思是索引的作用相當(dāng)于圖書的目錄,可以根據(jù)目錄中的頁碼快速找到所需的內(nèi)容。
一個索引是存儲的表中一個特定列的值數(shù)據(jù)結(jié)構(gòu)。索引是在表的列上創(chuàng)建。要記住的關(guān)鍵點是索引包含一個表中列的值,并且這些值存儲在一個數(shù)據(jù)結(jié)構(gòu)中。請牢記這一點:索引是一種數(shù)據(jù)結(jié)構(gòu)。一個好的數(shù)據(jù)庫表設(shè)計,從一開始就應(yīng)該考慮添加索引,而不是到最后發(fā)現(xiàn)慢SQL了,影響業(yè)務(wù)了才來補(bǔ)救。其實我在工作經(jīng)歷當(dāng)中,由于新建表或新加字段后,忘記添加索引也造成了多次生產(chǎn)事故,記憶猶新!!!
在沒有GUI工具的情況下,可以使用以下命令查看索引:

上述ad_article表中有兩個索引,Key_name中有顯示:
- PRIMARY主鍵索引,Seq_in_index索引序號為1,從1開始,Collation為“A”表示升序(或NULL無分類),對應(yīng)字段是id
- idx_cid是自建索引,由cid、available、id三個字段組成,分別對應(yīng)序號1,2,3
表中大部分信息都挺好理解的,倒是Index_type=BTREE這塊內(nèi)容很多人不懂其意思,其實通過GUI工具創(chuàng)建索引時也會有BTREE 的顯示,先著重了解一下。

BTREE
在計算機(jī)數(shù)據(jù)結(jié)構(gòu)(不懂?dāng)?shù)據(jù)結(jié)構(gòu)的自行充電)體系中,為了加速查找的速度,常見的數(shù)據(jù)結(jié)構(gòu)有兩種:
- Hash哈希結(jié)構(gòu),例如Java中的HashMap,這種數(shù)據(jù)組織結(jié)構(gòu)可以讓查詢/插入/修改/刪除的平均時間復(fù)雜度都為O(1);
- Tree 樹 結(jié)構(gòu) , 這種數(shù)據(jù)組織結(jié)構(gòu)可以讓查詢/插入/修改/刪除的平均時間復(fù)雜度都為O(log(n));
注:時間復(fù)雜度O是數(shù)據(jù)結(jié)構(gòu)課程中的基礎(chǔ)內(nèi)容,不明白同學(xué)的自行充電。O(1)的意思是不管N多大其速度都是恒定的,O(log(N))的意思是不管N多大,都要花費N的對數(shù)次時間。
問題來了:即然不管讀還是寫,Hash這種類型比Tree樹這種類型都要更快一些,那為什么MySQL的開發(fā)者既使用Hash類型做為索引,又使用了BTREE呢?
話說回來,還是跟SQL應(yīng)用場景有關(guān)系,前文中我們找"ZhangSan"用戶的SQL:
select name,age,address from employee where name='ZhangSan'
確實用HASH索引更快,因為每次都只查詢一條信息(重名的雇員姓名也才幾條而已),但實際上業(yè)務(wù)對于SQL的應(yīng)用場景是:
- orderby 需要排個序
- groupby 還要分個組
- 還要比較大小 大于或小于等等
這種情況下如果繼續(xù)用HASH類型做索引結(jié)構(gòu),其時間復(fù)雜度會從O(1)直接退化為O(n),相當(dāng)于全表掃描了,而Tree的特性保證了不管是哪種操作,依然能夠保持O(log(n))的高效率,有種我自巋然不動的趕腳!所以拋開應(yīng)用場景談設(shè)計其實是耍流浪(比如很多java程序員被安利阿里的fastjson比jackson快,故而拋棄jackson一樣),實際上MySQL中也支持HASH類型的索引,但不是主流。
那MySQL中的BTREE和TREE又有啥聯(lián)系與區(qū)別呢?先來看看傳統(tǒng)的二叉樹:

二叉樹是大家熟知的一種樹,用它來做索引行不行,可以是可以,但有幾個問題:
- 如果索引數(shù)據(jù)很多,樹的層次會很高(只有左右兩個子節(jié)點),數(shù)據(jù)量大時查詢還是會慢
- 二叉樹每個節(jié)點只存儲一個記錄,一次查詢在樹上找的時候花費磁盤IO次數(shù)較多
所以它并不適合直接拿來做索引存儲,算法設(shè)計人員在二叉樹的基礎(chǔ)之上進(jìn)行了變種,引入了BTREE的概念(詳情可自行查詢)
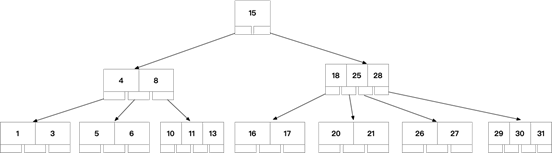
如上圖可知BTREE有以下特點:
- 不再是二叉搜索,而是N叉搜索,樹的高度會降低,查詢快
- 葉子節(jié)點,非葉子節(jié)點,都可以存儲數(shù)據(jù),且可以存儲多個數(shù)據(jù)
- 通過中序遍歷,可以訪問樹上所有節(jié)點
BTREE被作為實現(xiàn)索引的數(shù)據(jù)結(jié)構(gòu)被創(chuàng)造出來,是因為它能夠完美的利用“局部性原理”,其設(shè)計邏輯是這樣的:
- 內(nèi)存讀寫快,磁盤讀寫慢,而且慢很多
- 磁盤預(yù)讀:磁盤讀寫并不是按需讀取,而是按頁預(yù)讀,一次會讀一頁的數(shù)據(jù),每次加載一些看起來是冗余的數(shù)據(jù),如果未來要讀取的數(shù)據(jù)就在這一頁中,可以避免未來的磁盤讀寫,提高效率(通常,一頁數(shù)據(jù)是4K)
- 局部性原理:軟件設(shè)計要盡量遵循“數(shù)據(jù)讀取集中”與“使用到一個數(shù)據(jù),大概率會使用其附近的數(shù)據(jù)”,這樣磁盤預(yù)讀能充分提高磁盤IO效能
早先的MySQL就是使用的BTREE做為索引的數(shù)據(jù)結(jié)構(gòu),隨著時間推移,B樹發(fā)生了較多的變種,其中最常見的就是B+TREE變種,現(xiàn)在MySQL用的就是這種,示意如下:
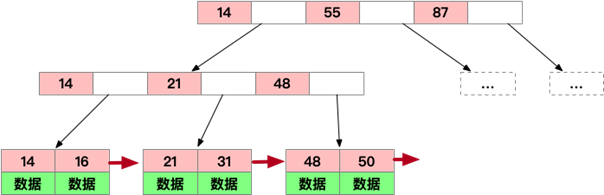
B+TREE改進(jìn)點及優(yōu)勢所在:
- 仍然是N叉樹,層級小,非葉子節(jié)點不再存儲數(shù)據(jù),數(shù)據(jù)只存儲在同一層的葉子節(jié)點上,B+樹從根到每一個節(jié)點的路徑長度一樣,而B樹不是這樣
- 葉子之間,增加了鏈表(圖中紅色箭頭指向),獲取所有節(jié)點,不再需要中序遍歷,使用鏈表的next節(jié)點就可以快速訪問到
- 范圍查找方面,當(dāng)定位min與max之后,中間葉子節(jié)點,就是結(jié)果集,不用中序回溯(范圍查詢在SQL中用得很多,這是B+樹比B樹最大的優(yōu)勢)
- 葉子節(jié)點存儲實際記錄行,記錄行相對比較緊密的存儲,適合大數(shù)據(jù)量磁盤存儲;非葉子節(jié)點存儲記錄的PK,用于查詢加速,適合內(nèi)存存儲
- 非葉子節(jié)點,不存儲實際記錄,而只存儲記錄的KEY的話,那么在相同內(nèi)存的情況下,B+樹能夠存儲更多索引
可以來初步計算一下:假設(shè)key、子樹節(jié)點指針均占用4B,則B樹一個節(jié)點占用4 + 4 = 8B,一頁頁面大小4KB,則N = 4 * 1024 / 8B = 512,一個512叉的B樹,1000w的數(shù)據(jù),深度最大 log(512/2)(10^7) 約等于4。對比二叉樹如AVL的深度為log(2)(10^7) 約為24,相差了5倍以上!
假如一個節(jié)點大小是4KB,一個KEY有8字節(jié),一頁可以存4000/8=500個KEY,根據(jù)N叉樹特點,就算一層500叉節(jié)點,則:
第一層樹:1個節(jié)點,1*500KEY , 大小4K
第二層樹:500節(jié)點 500*500=25萬個KEY,500*4K=2M
第三層樹:500 * 500節(jié)點 500*500*500=1.2億KEY,500*500*4K=1G
如果沒算錯,1G空間,只用三層樹結(jié)構(gòu),可以存1.2億行數(shù)據(jù)的KEY,B+樹牛掰不?
所以B+TREE索引只用占用很少的內(nèi)存空間,卻大大提升了查詢效率(不論是單個查詢、范圍查詢還是有序性查詢),并且還減少了磁盤讀寫,所以好的算法與數(shù)據(jù)結(jié)構(gòu)是可以省錢的。
說完BTREE,在'showindex from ad_article'結(jié)果集中有一列為Cardinality的值,它的作用也非常的大,稱之為:索引基數(shù)

Cardinality 索引基數(shù)
索引基數(shù)簡單的說就是:你索引列的唯一值的個數(shù),如果是復(fù)合索引就是唯一組合的個數(shù)。這個數(shù)值將會作為MySQL優(yōu)化器對語句執(zhí)行計劃進(jìn)行判定時依據(jù)。如果唯一性太小,那么優(yōu)化器會認(rèn)為這個索引對語句沒有太大幫助,而不使用索引。cardinality值越大,就意味著,使用索引能排除越多的數(shù)據(jù),執(zhí)行也更為高效。
舉個簡單例子來說明:比如有一張表有A、B、C列,數(shù)據(jù)情況如下:
A B C
1 1 1
1 1 2
1 2 1
1 2 2
2 1 1
2 1 2
2 2 1
2 2 2
- 如果對A列進(jìn)行索引,那么它的cardinality基數(shù)值為2,因為只有1,2兩種值
- 如果對A、B兩列做復(fù)合索引,那么它的cardinality基數(shù)值為4,因為值的組合為(11),(1 2),(2 1),(2 2)
- 如果對A、B、C做復(fù)合索引,則它的cardinality基數(shù)值為8
當(dāng)有多個索引可用時,mysql會自動依據(jù)cardinality大的值來進(jìn)行SQL索引選擇優(yōu)化。如果現(xiàn)在再問你“為什么數(shù)據(jù)庫都有PK”,你怎么答?因為PK的數(shù)據(jù)均不一樣啊,做索引了后查詢起來效果才快啊,因為cardinality值很高,是不是?另一種問法常見于判斷題,問你“數(shù)據(jù)庫索引通常要放在選擇性差的列上”,你以前可能還不明白為什么,其背后邏輯就是索引的cardinality值啊,選擇性差意味著重復(fù)數(shù)據(jù)少,索引才高效嘛。
但回到我們自己的例子,數(shù)據(jù)庫中有數(shù)據(jù)值61行,但是cardinality=59并不準(zhǔn)確,是因為它不會自動更新,需要通過analyzetable來進(jìn)行更新,示例如下:
mysql>analyze local table ad_article;
優(yōu)化以后結(jié)果為:
索引基數(shù)更加準(zhǔn)確一些了。

索引類型
MySQL中有以下索引類型:
UNIQUE唯一索引 該索引其含義是被標(biāo)定義唯一索引的列,不允許出現(xiàn)重復(fù)的數(shù)據(jù), 但可以有NULL值。舉例來講,假如有A、B兩個字段,建立唯一索引:
A B
1 1
1 2
1 1 // 這一行數(shù)據(jù)無法插入,因為與第一條數(shù)據(jù)重復(fù),數(shù)據(jù)庫底層報錯DuplicateKeyException 1 1
唯一索引有利有弊,好處是:如果你的程序不好處理界面端的重復(fù)提交,或者因為數(shù)據(jù)的重復(fù)導(dǎo)致程序出錯誤,可以通過創(chuàng)建唯一索引來解決問題,當(dāng)然不要為了設(shè)置唯一索引而設(shè)置索引,索引還是要有用處的。其次在設(shè)置了唯一索引時,萬一真要發(fā)生變更,支持重復(fù)數(shù)據(jù)怎么辦?MySQL提供了兩種補(bǔ)救辦法:
- 自動替換為新的值,可以用ONDUPLICATE KEY UPDATE xxx= VALUES(xxx)
- 忽略插入是 insert ignore into
INDEX普通索引允許出現(xiàn)相同的索引內(nèi)容,平時創(chuàng)建的索引通常就是普通索引,利用提升查詢數(shù)據(jù)性能
PRIMARY KEY主鍵索引 不允許出現(xiàn)相同的值,且不能為NULL值,一個表只能有一個primary_key索引,常見于ID字段
fulltext index 全文索引 上述三種索引都是針對列的值發(fā)揮作用,但全文索引,可以針對值中的某個單詞,比如一篇文章中的某個詞,然而并沒有什么卵用,因為只有myisam引擎以及英文支持,并且效率讓人不敢恭維,要全文搜索還是建議使用Luence、Solr、ES等方案,更專業(yè)且強(qiáng)大一些。

索引的創(chuàng)建與使用
ALTER TABLE 適用于表創(chuàng)建完畢之后再添加
ALTERTABLE 表名 ADD 索引類型 (unique,primary key,fulltext,index)[索引名](字段名)
CREATE INDEX可對表增加普通索引或UNIQUE索引
CREATE INDEXindex_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name(column_list)
另外,還可以在建表時添加:
CREATE TABLE mytable (
... //中間字段忽略
PRIMARY KEY (`id`),
UNIQUE KEY `unique1`(`username`), -- 索引名稱,可要可不要,不要就是和列名一樣
KEY `index1` (`nickname`),
FULLTEXT KEY `intro` (`intro`)
) ENGINE=MyISAMAUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='測試表';
一張表字段有多有少,該在哪些列上創(chuàng)建索引呢?其實新建索引也是有一定的原則的,建什么索引,建在哪些字段上,有以下一些原則與技巧可參考:
- 在維度高或選擇性差的列創(chuàng)建索引 說人話就是數(shù)據(jù)列中不重復(fù)值出現(xiàn)的個數(shù),這個數(shù)量越高,維度就越高(如數(shù)據(jù)表中存在8行數(shù)據(jù)a,b ,c,d,a,b,c,d這個表的維度為4)。要為維度高的列創(chuàng)建索引,如性別和年齡,那年齡的維度就高于性別,性別這樣的列不適合創(chuàng)建索引,因為維度過低,只有兩三種值。
- 對 where,on,group by,order by 中出現(xiàn)的列使用索引,索引一般多設(shè)置在條件列上,顯示列通常少設(shè)置索引
- 對較小的數(shù)據(jù)列使用索引 ,這樣會使索引文件更小,同時內(nèi)存中也可以裝載更多的索引鍵,例如有一個字段存文本內(nèi)容,新聞、資訊類那種的,內(nèi)容超大,你為它設(shè)置索引就是腦袋被門夾了。
- 為較長的字符串使用前綴索引,比如有個姓名字段firstname,varchar(50)個長,可以用
alter table employee add key(firstname(5))
來設(shè)置前綴索引,為什么這里只取前5個字符進(jìn)行索引呢?是因為可以通過
select 1.0 *count(distinct left(firstname,5)) / count(*) from employee
算法得到前幾個字母對標(biāo)數(shù)據(jù)的覆蓋率,覆蓋率超過31%黃金值就可以使用前綴索引。
- 使用組合索引,可以減少文件索引大小,在使用時速度要優(yōu)于多個單列索引
- 索引也不是越多越好,不要過多創(chuàng)建索引,除了增加額外的磁盤空間外,對于DML操作的速度影響很大,因為其每增刪改一次就得從新建立索引
說了創(chuàng)建索引,接下來就是使用索引,如果認(rèn)真研讀過前面的“執(zhí)行計劃”,SQL用到哪些索引,用了索引沒有一目了然,但是有一些情況就是不會走索引,先來一些簡單的示例說明:
SELECT sname FROM stu WHERE age+10=30; --不會使用索引,因為有索引列參與了計算
SELECT sname FROM stu WHERE LEFT(`date`,4) <1990; -- 不會使用索引,因為使用了函數(shù)運算,原理與上面相同
SELECT * FROM table WHERE uname LIKE'前綴%' -- 走索引
SELECT * FROM table WHERE uname LIKE "%關(guān)鍵字%"-- 不走索引
SELECT * FROM table WHERE a=1 -- a列為char字符類型,用整數(shù)找不走索引,a='1'才走索引
SELECT * FROM table WHEREdname='xxx' or loc='xx' or deptno=45
-- 如果條件中有or,即使其中有條件帶索引也不會使用。換言之,就是要求使用的所有字段,都必須建立索引,建議大家盡量避免使用or關(guān)鍵字
-- 正則表達(dá)式,regexp不走索引
-- 表中數(shù)據(jù)不多,只有幾十幾百條,MySQL評估使用全表掃描要比使用索引快,也不使用索引,不要大驚小怪
以上都是單表查詢操作,多表關(guān)聯(lián)查詢才是業(yè)務(wù)開發(fā)的“常見姿勢”,假如有一個查詢:
select a,b,c from A join B join C on a=b and b=c;
三表join關(guān)聯(lián),假設(shè)三個表每個均有2000條記錄,在沒有添加索引時,則結(jié)果會進(jìn)行2000*2000*2000=8000000000一共80億次檢索(因為一不小心就是一個笛卡爾乘積的恐怖掃描),只有在加了索引后,第一張表會全表掃描2000次,其余的關(guān)聯(lián)表基本是range區(qū)間掃描,這樣掃描次數(shù)就會降低很多很多,并且關(guān)聯(lián)表時,建議多用leftjoin以少聯(lián)多減少掃描次數(shù)。
有些時候發(fā)現(xiàn)明明創(chuàng)建了索引,但是因為一些原因并沒有使用索引,mysql支持強(qiáng)制走索引,比如:
select* from table where a=1 force index(PRI,my_index) --強(qiáng)制主鍵索引和自己創(chuàng)建的索引
與之相反,還可以禁止某個索引:
select* from table where a=1 ignore index(PRI,my_index) --禁止使用索引

復(fù)合索引執(zhí)行順序
復(fù)合索引的執(zhí)行順序是有講究的,還是以之前的案例舉例:

表有一個主鍵索引及一個復(fù)合索引,復(fù)合索引名稱:idx_cid,字段順序分別是:cid,available及id
只用cid執(zhí)行分析:

結(jié)果顯示用到了idx_cid,接下來再看第二個字段的分析:

沒有走idx_cid索引,全表掃描,接下來再看第三個的分析:

因為id本身就是主鍵,所以也不會走idx_cid索引,而是走主鍵索引,假設(shè)id不是主鍵索引,則也不會走idx_cid索引。
接下來再測試兩兩組合,先看cid +available組合:
結(jié)果顯示用到了idx_cid,再看cid+id組合:

結(jié)果顯示也用到了idx_cid,再看available+id組合:

結(jié)果是走的主鍵索引,并沒有走idx_cid復(fù)合索引,于是結(jié)果很清晰了,MySQL中的復(fù)合索引有順序,且很重要,查詢條件的順序不能隨意亂寫。假設(shè)A、B、C三個字段索引按A+B+C順序創(chuàng)建的索引:
A --走索引
B --不走索引
C --不走索引
A + B 或 B + A -- 走索引
B + C 或 C + B -- 不走索引
A + B + C 或 B + C + A 或 C + B + A --走索引
小結(jié):在復(fù)合索引中,索引第一位的column很重要,只要查詢語句包含了復(fù)合索引的第一個條件,基本上就會使用到該復(fù)合索引(可能會使用其他索引)。在建復(fù)合索引的時候應(yīng)該按照column的重要性從左往右建。

索引的坑
既然索引這么好,我們是不是應(yīng)該盡可能多用索引呢?并不是。
首先,不要盲目的創(chuàng)建索引,應(yīng)只為那些查詢操作頻繁的列創(chuàng)建索引,創(chuàng)建索引會使查詢操作變得更加快速,但是會降低增加、刪除、更新操作的速度,因為執(zhí)行這些操作的同時會對索引文件進(jìn)行重新排序或更新;
其次,在互聯(lián)網(wǎng)應(yīng)用中,查詢的語句遠(yuǎn)遠(yuǎn)大于DML的語句,為一個大表(比如千萬級數(shù)據(jù))新建索引時是一個需要特別慎重的事情,經(jīng)常出現(xiàn)“翻車”導(dǎo)致“車毀人亡”的事故,為什么?因為線上系統(tǒng)在被人使用,如果這時候開發(fā)或者運維人員執(zhí)行一個創(chuàng)建索引的語句,容易導(dǎo)致表被鎖死,所有操作排隊無法被響應(yīng),時間一長容易導(dǎo)致業(yè)務(wù)崩潰,形成鏈?zhǔn)竭B鎖反應(yīng),讓業(yè)務(wù)蒙受巨大損失。百萬或千萬級數(shù)據(jù)庫,大表加索引有一個比較好的方法:online-schema-change,有興趣可自行網(wǎng)上搜索,此文不再贅述。
來源:本文內(nèi)容搜集或轉(zhuǎn)自各大網(wǎng)絡(luò)平臺,并已注明來源、出處,如果轉(zhuǎn)載侵犯您的版權(quán)或非授權(quán)發(fā)布,請聯(lián)系小編,我們會及時審核處理。
聲明:江蘇教育黃頁對文中觀點保持中立,對所包含內(nèi)容的準(zhǔn)確性、可靠性或者完整性不提供任何明示或暗示的保證,不對文章觀點負(fù)責(zé),僅作分享之用,文章版權(quán)及插圖屬于原作者。


聯(lián)系郵箱:service#改成@jsedu114.com
地 址:中國●江蘇
南京市秦淮區(qū)洪武路359號1506室
Copyright?2013-2024 JSedu114 All Rights Reserved. 江蘇教育信息綜合發(fā)布查詢平臺保留所有權(quán)利
![]() 蘇公網(wǎng)安備32010402000125
蘇ICP備14051488號-3技術(shù)支持:南京博盛藍(lán)睿網(wǎng)絡(luò)科技有限公司
蘇公網(wǎng)安備32010402000125
蘇ICP備14051488號-3技術(shù)支持:南京博盛藍(lán)睿網(wǎng)絡(luò)科技有限公司
南京思必達(dá)教育科技有限公司版權(quán)所有 百度統(tǒng)計




 新浪微博
新浪微博


